Have I Played Apex with that guy?
Last updated: 2023-07-17 (2 years ago)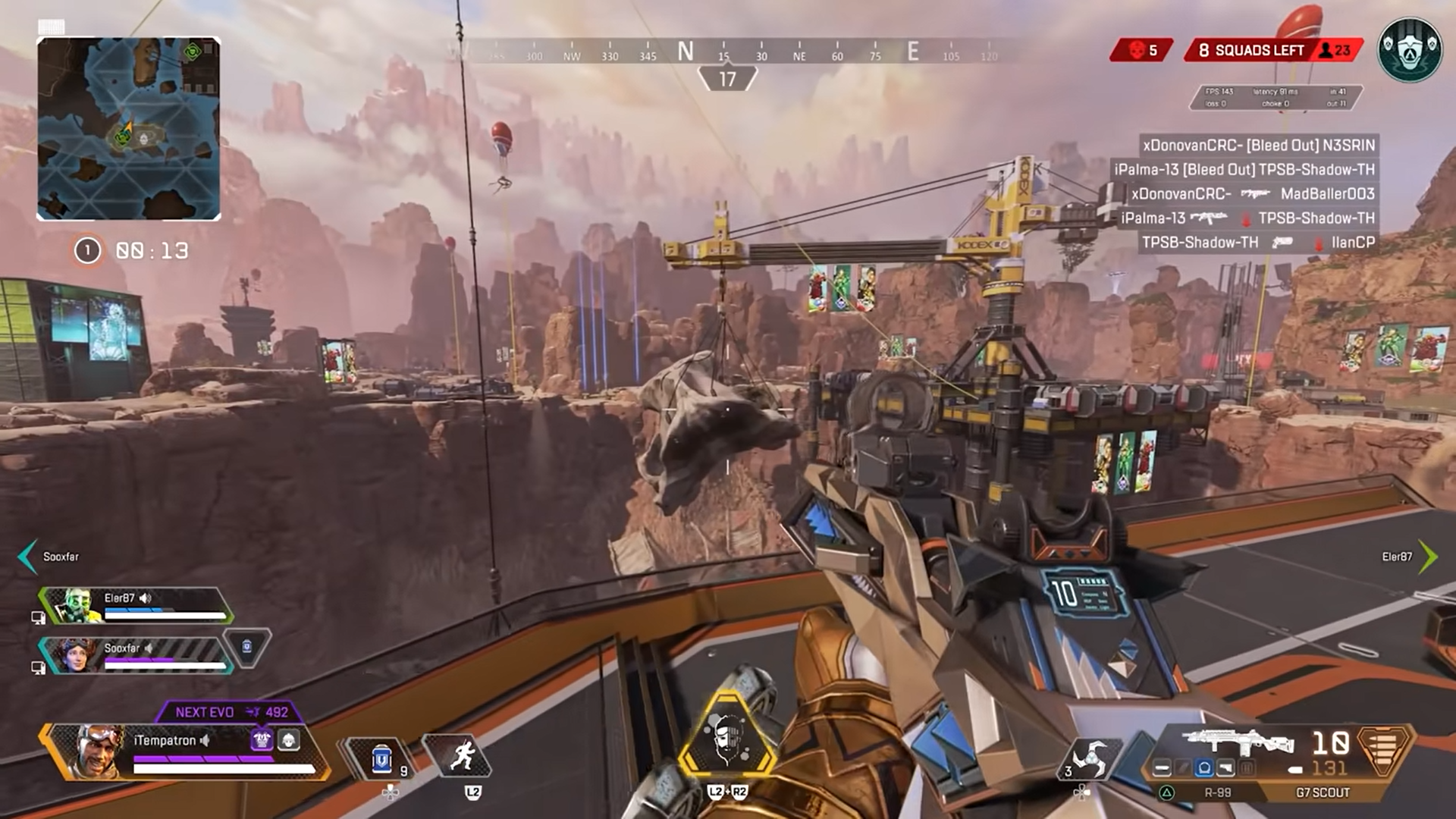 Basic Apex Legends' in-game screen capture
Basic Apex Legends' in-game screen captureTips for an efficient seach
- Avoid letters that are not from the roman alphabet, as they are not recognised by the engine;
- Avoid spaces, as they are not supported;
- The search is case sensitive, meaning 'a' and 'A' won't match;
- If your username has special characters or spaces, replace them with an underscore '_' and use the partial search;
- If your username is particularly lengthy, try searching for a subset, as 'LongUsername' will also match 'VeryLongUsername';
- Enter 'pinged' or 'Enemy' to get many results!
How does it work?
Overview
- Downloading YouTube videos
- Optical Character Recognition (OCR)
- Storage and Querying of video frames
- Limitations and Improvements
Downloading Youtube videos
- youtube-dl to check available formats and get a download URL. It is a command-line tool that can be run through a Python script;
- Open CV for Python to process the video feed, which is a Python library.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import youtube_dl
# Youtube video URL
url = "..."
downloadOptions = {}
# Instanciates the downloader
ytDownloadHandler = youtube_dl.YoutubeDL(downloadOptions)
# Fetches video metadata
infoDict = ytDownloadHandler.extract_info(url, download=False)
formats = infoDict.get('formats',None)
for f in formats:
# Our OCR algorithm needs a good quality image, we only process 1440p60
if f.get('format_note',None) == '1440p60':
url = f.get('url',None)
videoCapture = cv2.VideoCapture(url)
# ... rest of the video processing is happening here
videoCapture.release()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# The video capture we ended up with previously
videoCapture = cv2.VideoCapture(url)
currentIndex = 0
frameCount = 0
# Emergency hatch, we cap the max number of frames at 1000.
while currentIndex<1000:
# Reads the next frame, returns false if none
retVal, frame = videoCapture.read()
if not retVal:
print("No more frames, input stream is over. Exiting ...")
break
currentIndex+=1
# ... image optimisation steps are happening here
# Saving the image as a png file
outputFileName =r"D:\outputFolder\image-" + str(currentIndex) + ".png"
cv2.imwrite(outputFileName, frame)
#Skip 360 frames, i.e. 6 seconds for 60 fps
frameCount += 360
videoCapture.set(1,frameCount)At this point, we are extracting 1 frame every 6 seconds of the video, and creating a png file for each ('image-1.png', 'image-2.png', ...). That's exactly what we need for the next step!
Frame OptimisationDeep dive into the frame optimisation process.
Let's take a step back and look at how we've transformed our frames so far.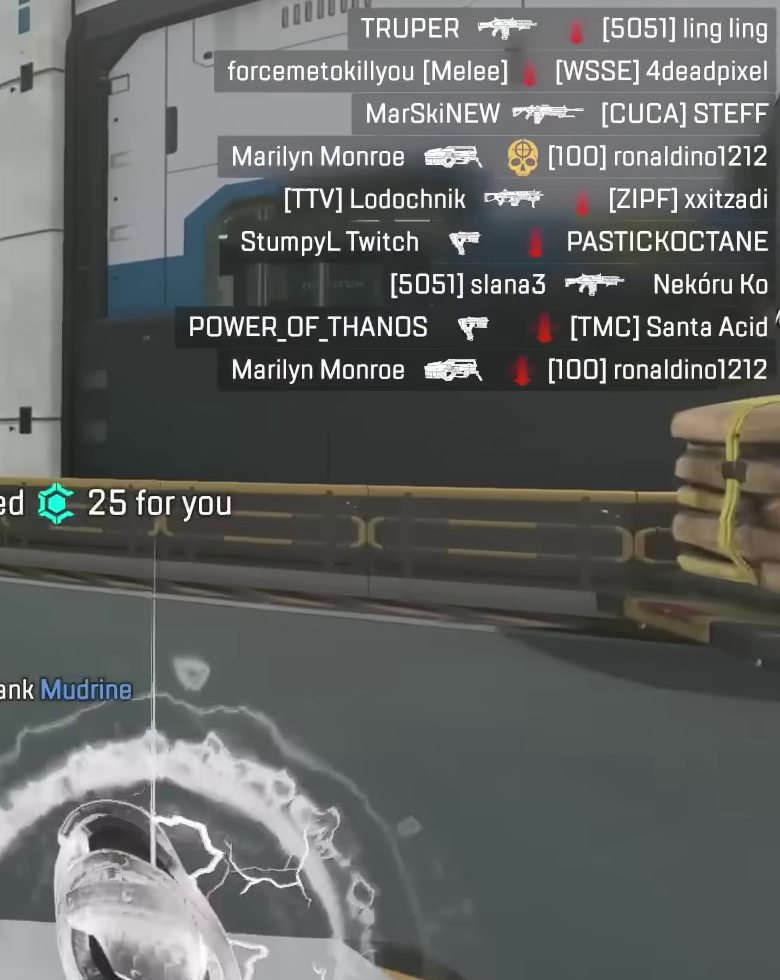 Base frame (cropped)
Base frame (cropped) Binarised frame (cropped)
Binarised frame (cropped)Optical Character Recognition (OCR)
"Optical character recognition or optical character reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text [...]"
Converting an image of text, into text we can handle with a computer, that's exactly what we are trying to accomplish. Several libraries exist to help us perform OCR, however we will stick with Python once again, since we've already used it in the previous step, time to introduce:
- pytesseract, a Python OCR tool, to do the heavy lifting. The library is leveraging Google's Tesseract-OCR Engine under the hood;
- Open CV for Python, which we used previously, we'll simply use it to open the image file in our Python script.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import cv2
import pytesseract
from pathlib import Path
# Loads up the tesseract module
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
### This loop searches all png files in the given folder.
# Then it runs the OCR tool on each one, to produce a block of text containing the kill feed.
for framePngPath in Path(r'D:/path/to/frames/').glob('*.png'):
# Reads a frame
im = cv2.imread(f"D:/path/to/frames/{framePngPath.name}")
# Runs OCR
OcrKillFeed = pytesseract.image_to_string(im)
print('Text output:', OCRkillfeed)Above: frame - input / Right side: text - outputTRUPER “7
{s051]
ling
forcemetokillyou [Melee] [WSSE] 4deadpixel
MarSkiNEW *7=e= [CUCA] STEFF
Marilyn Monroe #6 € [100] ronaldinol212
[TV] Lodochnik over
[ZIPF] xxitzadi
= StumpyL Twitch ¥
PASTICKOCTANE
[S051] slana3 “9 NekéruKo
POWEROFTHANOS
[TMC] Santa Acid “%""®
vw
Marilyn Monroe ==
(100) ronaldinoi212
——
- 25 foryou.
(AL
—
hank Mudrine- Overall results are remarkable, almost every gamer tag has been detected flawlessly. Internally, the OCR tool is relying on an english dictionnary to produce its result, but even non-english usernames have been pretty well extracted, like 'MarSkiNEW' or 'xxitzadi';
- A couple of non-english usernames have one or two characters that were incorrectly detected, like 'POWER_OF_THANOS' missing underscores '_', and 'Nekóru Ko' not getting the foreign 'ó'. We will keep in mind these shortcomings once we'll start querying our data;
- The most obvious problem is the amount of noise, especially coming from the weapon icons located between each username. They are generating a couple of characters that we would like to discard because they will trigger false positive when we start querying the data.
'Optimised' VS 'non-optimised' frame OCR performance comparison
Storing and Querying of video frames
- re, a Python module providing support for regular expressions. We'll use it to clean up our results and filter our as much noise as possible.
- pymongo, a Python module providing tools for interacting with a MongoDB database.
- js-lenvenshtein, a Javascript library providing support for implementing a partial search.
- A 'perfect match' search, as the name implies, will retrieve results if they match letter for letter any given input. For this job, we will be using regular expressions;
- A 'close match' search, or partial search, will retrieve results if they match the given input, allowing an error margin of 1, 2 or 3 characters. For that job, we will be using an algorithm called 'levenshtein distance' that can calculate how 'similar' two sets of characters are.
Perfect match search
1
2
3
4
5
6
7
8
9
OcrKillFeed = pytesseract.image_to_string(im)
print('Text output:', OCRkillfeed)
# Inserts the result into the 'frames' collection (we're dumping it as is) :
insert_result = framesCollection.insert_one({
"videoId": 1, # each video has a unique ID (1 is just an example)
"frameNumber": 12 # each png file has a number that we will fill out here (12 is also just an example)
"usernames": OCRkillfeed,
})1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
MongoDB "frame" document:
{
"_id": {
"$oid": "437535263cf465664f01421"},
"videoId": <videoID>,
"frameNumber": "frame0",
"usernames": "TRUPER = [5051] ling ting
forcemetokillyou [Melee] [WSSE] 4deadpixel
MarSkiNEW >= [CUCA] STEFF
Marilyn Monroe a2 2 [100] ronaldinol212
[TTV] Lodochnik ore [ZIPF] xxitzadi
StumpyL Twitch =e PASTICKOCTANE
[5051] slana3 4 =Nekoru Ko
POWER.OFTHANOS [TMC] Santa Acid’
Marilyn Monroe «gar [100] ronaldino!212
id |. 25 for yo"
}What happens next?Upon submitting a gamer tag for the search, we will look for a match in the database.
That's the 'perfect search' run-down out of the way, let's switch our attention to the 'partial search'.Close match search
Indeed, a requirement is to store a list of actual usernames, instead of a block of text where everything is all mixed up. So we are directing our efforts towards generating a list of username, for each frame, for each video. Only then will we be able to run the 'partial search'.
Let's go back to the Python script one last time:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
isInVideoCollectionAlready = False
for framePngPath in Path(r'D:/path/to/frames/').glob('*.png'):
im = cv2.imread(f"D:/path/to/frames/{framePngPath.name}")
OcrKillFeed = pytesseract.image_to_string(im)
# This step is where we are filtering out as much noise as possible from the OCR results, to keep only actual usernames.
# It is explained in finer details just below this snippet.
OCR_usernames_array = re.findall(extractUsernamesRegex, OCRkillfeed)
# We need to extract the frame number from the png file
# Opted out of the snippet for simplicity sake
frameNumber = <frameNumber>
# No need to continue if no usernames were found
if (OCR_usernames_array == []):
continue
# Checks if the video currently processed is already in the DB, if so we just want to update and add to it
if (isInVideoCollectionAlready == False):
videoDoc = videosCollection.find_one({ "name": <nameOfTheVideoBeingProcessed> })
if (videoDoc != None):
isInVideoCollectionAlready = True
if (isInVideoCollectionAlready):
# Updates the video document to add the frame and its reported matches:
videoUpdate_result = videosCollection.update_one(
{ "name": <nameOfTheVideoBeingProcessed> },
{ "$set": { f"usernamesOccurences.{frameName}": OCR_usernames_array }
})
else: # If it's not in the DB, we insert a new document
videoObject = { "name": inputFiles[useVideoNumber].name,
"usernamesOccurences": {} }
videoObject["usernamesOccurences"][frameName] = OCR_usernames_array
# Inserts the result into the 'videos' collection:
videoInsert_result = videosCollection.insert_one(videoObject)
print("Done")- line 8, is where the magic happens, we're using the regex to turn the block of detected text, into an array of individual usernames. This step is detailed in the explanation box below;
- line 15, if no usernames were detected on the frame, no further processing is needed, we just pass onto the next one;
- line 19, the block is used to determine whether we need to create a new document for the current video, or if we just have to update an existing one.
- line 24 and 30, these blocks respectively update or insert the username array into the database.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
MongoDB "video" document:
{
"_id": { "$oid": "437535263cf465664f01422" },
"name": <videoName>,
"usernamesOccurences": {
"frame0": ["TRUPER","ling","ting","forcemetokillyou","4deadpixel","MarSkiNEW","STEFF","Marilyn","Monroe", ...rest of the usernames ],
... rest of the frames
"frame99": ["ARADEN"] },
"date": { "$date": {
"$numberLong": "1673863200000"
}},
"title": <videoTitle>,
"creator": "ITemp",
"url": <videoUrl>
}- 'name', 'title', 'creator', 'date' and 'url' represent the video's metadata, and will simply be used to nicely display the search results;
- 'usernamesOccurences' is an object, it has one key for each frame recorded for that particular video. For example, 'usernamesOccurences.frame0' is the array of all usernames found in the very first frame for that video.
Filtering noise out of the OCR outputThe exact regular expression was left out in the previous snippet to keep it concise, now we can break it down in details.
Since we've reached a stage where we finally have a clean list of usernames nicely stored in MongoDB, we can put together the partial search. As stated at the beginning of this section, we'll use a node package called 'js-levenshtein' that is using an implementation of the 'Wagner-Fischer' algorithm.The 'Levenshtein Distance' is nothing else than the distance between two strings, i.e. how many substitutions does it take to transform one into the other. Let's see a couple of examples:
- 'mouse' and 'moose' have a levenshtein distance equal to 1;
- 'mouse' and 'blouse' have a levenshtein distance equal to 2;
- 'mouse' and 'us' have a levensthein distance equal to 3. As we can see, capping the maximum distance at 3 already provide a pretty large leeway around the searched keyword. That is also why we are restricting the search to 4-characters usernames or more, otherwise a partial search would just yield to many useless results.
1
2
3
4
5
6
7
8
9
import levenshtein from 'js-levenshtein';
/* Simplified implementation details,
we are looping through the usernames from the DB
... */
const levDistance = levenshtein(/* username from the DB ->*/username, usernameInput /*<- username typed in the search box*/);
/* if the distance is below the threshold (can be 1, 2 or 3), we have a match! */
if (levDistance <= partialMatchMaxDifference) {
// ... deal with the match here
}Limitations and Improvements
Limitations:
- The search engine only covers 4 videos, as a proof of concept;
- Short or non-english usernames are not supported;
- In order to display search results in an inviting popup, frames images are stored on the server, thus imposing a size constraint to the project. Storing the frames isn't stricly necessary though, the database could be enough in itself.
- Extending support to more videos;
- Optimising the script reading frames from videos, as it can be quite slow, a couple of minutes per video, depending on the connection. Adding multi-threading would be a great improvment;
- Optimising what frames are read from the video, as sometimes if the 6-second window happens to capture a frame where the player is in a menu, no useful usernames will be found;
- Improving the regex filtering out noise, especially to add support to usernames with spaces;
- Extending support to more than the English language for the OCR tool;
- Highlighting matches on the web app's search result popup;
References
- https://stackoverflow.com/questions/66272740/extract-specific-frames-of-youtube-video-without-downloading-video
- https://docs.opencv.org/3.4/d8/dfe/classcv_1_1VideoCapture.html
- https://stackoverflow.com/questions/66272740/extract-specific-frames-of-youtube-video-without-downloading-video
- https://github.com/ytdl-org/youtube-dl/blob/master/README.md#readme
